I’m doing some work to refactor a complex piece of code, and I have a piece of memory that is allocated, then accessed via a struct pointer. This piece of code gets called a lot, so I wondered about the tradeoff of holding a pointer that is already casted to the right struct pointer vs the cost of another pointer in the object.
Note, those are objects that are created a lot, and used a lot. Those are not the kind of things that you would usually need to worry about. Because I wasn’t sure, I decided to test this out. And I used BenchmarkDotNet to do so:
public struct FooHeader
{
public long PageNumber;
public int Size;
}
[BenchmarkTask(platform: BenchmarkPlatform.X86,
jitVersion: BenchmarkJitVersion.LegacyJit)]
[BenchmarkTask(platform: BenchmarkPlatform.X64,
jitVersion: BenchmarkJitVersion.LegacyJit)]
[BenchmarkTask(platform: BenchmarkPlatform.X64,
jitVersion: BenchmarkJitVersion.RyuJit)]
public unsafe class ToCastOrNotToCast
{
byte* p;
FooHeader* h;
public ToCastOrNotToCast()
{
p = (byte*)Marshal.AllocHGlobal(1024);
h = (FooHeader*)p;
}
[Benchmark]
public void NoCast()
{
h->PageNumber++;
}
[Benchmark]
public void Cast()
{
((FooHeader*)p)->PageNumber++;
}
[Benchmark]
public void DirectCastArray()
{
((long*)p)[0]++;
}
[Benchmark]
public void DirectCastPtr()
{
(*(long*)p)++;
}
}
The last two tests are pretty much just to have something to compare to, because if needed, I would just calculate memory offsets manually, but I doubt that those would be needed.
The one downside of BenchmarkDotNet is that it takes a very long time to actually run those tests. I’ll save you the suspense, here are the results:
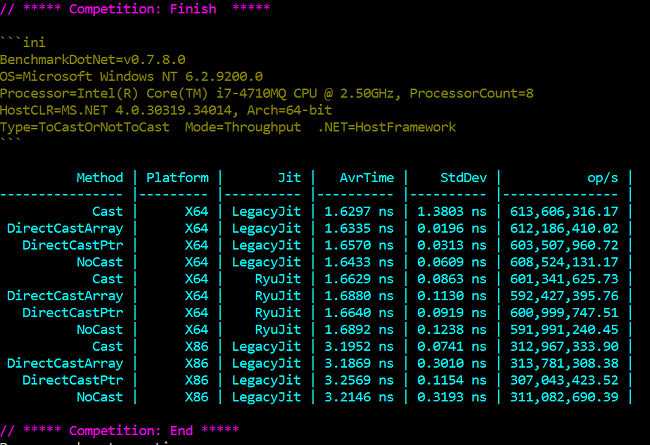
I was expected the NoCast method to be faster, to be honest. But the Cast method is consistently (very slightly) the fastest one. Which is surprising.
Here is the generated IL:

And the differences in assembly code are:
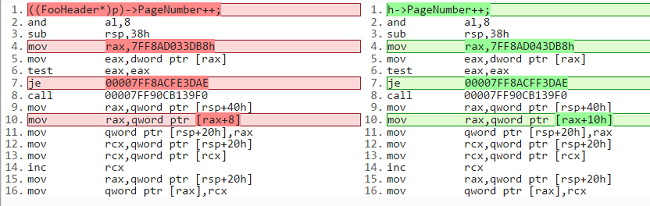
Note that I’m not 100% sure about the assembly code. I got it from the disassembly windows in VS, and it is possible that it changed what is actually going on.
So I’m not really sure why this would be difference, and it is really is a small difference. But it is there.
| Reference: | Micro benchmarks and hot paths from our NCG partner Oren Eini at the Ayende @ Rahien blog. |
